Artificial intelligence is advancing rapidly. In a few decades machines will achieve superintelligence and become self-improving. Soon after that happens we will launch a thousand ships into space. These probes will land on distant planets, moons, asteroids, and comets. Using AI and terabytes of code, they will then nano‑assemble local particles into living organisms. Each probe will, in fact, contain the information needed to create an entire ecosystem. Thanks to AI and advanced biotechnology, the species in each place will be tailored to their particular plot of rock. People will thrive in low temperatures, dim light, high radiation, and weak gravity. “Humanity” will become an incredibly elastic concept. In time our distant progeny will build megastructures that surround stars and capture most of their energy. Then the power of entire galaxies will be harnessed. Then life and AI—long a common entity by this point—will construct a galaxy-sized computer. It will take a mind that large about a hundred-thousand years to have a thought. But those thoughts will pierce the veil of reality. They will grasp things as they really are. All will be one. This is our destiny.
Then again, maybe not.
There are, of course, innumerable reasons to reject this fantastic tale out of hand. Here’s a quick and dirty one built around Copernicus’s discovery that we are not the center of the universe. Most times, places, people, and things are average. But if sentient beings from Earth are destined to spend eons multiplying and spreading across the heavens, then those of us alive today are special. We are among the very few of our kind to live in our cosmic infancy, confined in our planetary cradle. Because we probably are not special, we probably are not at an extreme tip of the human timeline; we’re likely somewhere in the broad middle. Perhaps a hundred-billion modern humans have existed, across a span of around 50,000 years. To claim in the teeth of these figures that our species is on the cusp of spending millions of years spreading trillions of individuals across this galaxy and others, you must engage in some wishful thinking. You must embrace the notion that we today are, in a sense, back at the center of the universe.
It is in any case more fashionable to speculate about imminent catastrophes. Technology again looms large. In the gray goo scenario, runaway self-replicating nanobots consume all of the Earth’s biomass. Thinking along similar lines, philosopher Nick Bostrom imagines an AI-enhanced paperclip machine that, ruthlessly following its prime directive to make paperclips, liquidates mankind and converts the planet into a giant paperclip mill. Elon Musk, when he discusses this hypothetical, replaces paperclips with strawberries, so that he can worry about strawberry fields forever. What Bostrom and Musk are driving at is the fear that an advanced AI being will not share our values. We might accidently give it a bad aim (e.g., paperclips at all costs). Or it might start setting its own aims. As Stephen Hawking noted shortly before his death, a machine that sees your intelligence the way you see a snail’s might decide it has no need for you. Instead of using AI to colonize distant planets, we will use it to destroy ourselves.
When someone mentions AI these days, she is usually referring to deep neural networks. Such networks are far from the only form of AI, but they have been the source of most of the recent successes in the field. A deep neural network can recognize a complex pattern without relying on a large body of pre-set rules. It does this with algorithms that loosely mimic how a human brain tunes neural pathways.
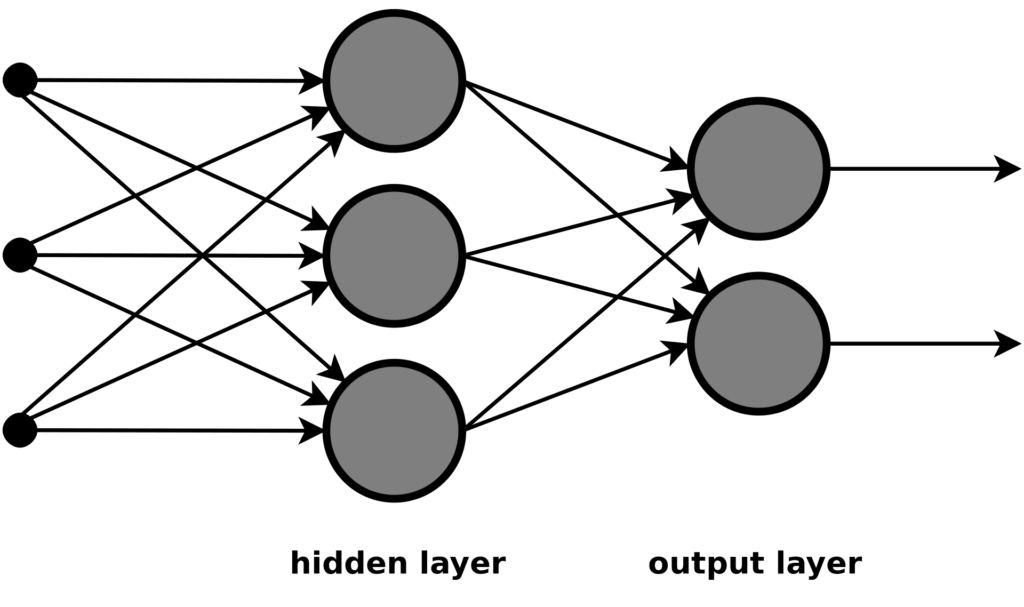
The neurons, or units, in a deep neural network are layered. The first layer is an input layer that breaks incoming data into pieces. In a network that looks at black-and-white images, for instance, each of the first layer’s units might link to a single pixel. Each input unit in this network will translate its pixel’s grayscale brightness into a numer. It might turn a white pixel into zero, a black pixel into one, and a gray pixel into some fraction in between. These numbers will then pass to the next layer of units. Each of the units there will generate a weighted sum of the values coming in from several of the previous layer’s units. The next layer will do the same thing to that second layer, and so on through many layers more. The deeper the layer, the more pixels accounted for in each weighted sum.
An early-layer unit will produce a high weighted sum—it will fire, like a neuron does—for a pattern as simple as a black pixel above a white pixel. A middle-layer unit will fire only when given a more complex pattern, like a line or a curve. An end-layer unit will fire only when the pattern—or, rather, the weighted sums of many other weighted sums—presented to it resembles a chair or a bonfire or a giraffe. At the end of the network is an output layer. If one of the units in this layer reliably fires only when the network has been fed an image with a giraffe in it, the network can be said to recognize giraffes.
A deep neural network is not born recognizing objects. The network just described would have to learn from pre-labeled examples. At first the network would produce random outputs. Each time the network did this, however, the correct answers for the labeled image would be run backward through the network. An algorithm would be used, in other words, to move the network’s unit weighting functions closer to what they would need to be to recognize a given object. The more samples a network is fed, the more finely tuned and accurate it becomes.
Some deep neural networks do not need spoon-fed examples. Say you want a program equipped with such networks to play chess. Give it the rules of the game, instruct it to seek points, and tell it that a checkmate is worth a hundred points. Then have it use a Monte Carlo method to randomly simulate games. Through trial and error, the program will stumble on moves that lead to a checkmate, and then on moves that lead to moves that lead to a checkmate, and so on. Over time the program will assign value to moves that simply tend to lead toward a checkmate. It will do this by constantly adjusting its networks’ unit weighting functions; it will just use points instead of correctly labeled images. Once the networks are trained, the program can win discrete contests in much the way it learned to play in the first place. At each of its turns, the program will simulate games for each potential move it is considering. It will then choose the move that does best in the simulations. Thanks to constant fine-tuning, even these in-game simulations will get better and better.
There is a chess program that operates more or less this way. It is called AlphaZero, and at present it is the best chess player on the planet. Unlike other chess supercomputers, it has never seen a game between humans. It learned to play by spending just a few hours simulating moves with itself. In 2017 it played a hundred games against Stockfish 8, one of the best chess programs to that point. Stockfish 8 examined 70 million moves per second. AlphaZero examined only 80,000. AlphaZero won 28 games, drew 72, and lost zero. It sometimes made baffling moves (to humans) that turned out to be masterstrokes. AlphaZero is not just a chess genius; it is an alien chess genius.
AlphaZero is at the cutting edge of AI, and it is very impressive. But its success is not a sign that AI will take us to the stars—or enslave us—any time soon. In Artificial Intelligence: A Guide For Thinking Humans, computer scientist Melanie Mitchell makes the case for AI sobriety. AI currently excels, she notes, only when there are “clear rules, straightforward reward functions (for example, rewards for points gained or for winning), and relatively few possible actions (moves).” Take IBM’s Watson program. In 2011 it crushed the best human competitors on the quiz show Jeopardy!, leading IBM executives to declare that its successors would soon be making legal arguments and medical diagnoses. It has not worked out that way. “Real-world questions and answers in real-world domains,” Mitchell explains, “have neither the simple short structure of Jeopardy! clues nor their well-defined responses.”
Even in the narrow domains that most suit it, AI is brittle. A program that is a chess grandmaster cannot compete on a board with a slightly different configuration of squares or pieces. “Unlike humans,” Mitchell observes, “none of these programs can ‘transfer’ anything it has learned about one game to help it learn a different game.” Because the programs cannot generalize or abstract from what they know, they can function only within the exactparameters in which they have been trained.
A related point is that current AI does not understand even basic aspects of how the world works. Consider this sentence: “The city council refused the demonstrators a permit because they feared violence.” Who feared violence, the city council or the demonstrators? Using what she knows about bureaucrats, protestors, and riots, a human can spot at once that the fear resides in the city council. When AI-driven language-processing programs are asked this kind of question, however, their responses are little better than random guesses. “When AI can’t determine what ‘it’ refers to in a sentence,” Mitchell writes, quoting computer scientist Oren Etzioni, “it’s hard to believe that it will take over the world.”
And it is not accurate to say, as many journalists do, that a program like AlphaZero learns “by itself.” Humans must painstakingly decide how many layers a network should have, how much incoming data should link to each input unit, how fast data should aggregate as it passes through the layers, how much each unit weighting function should change in response to feedback, and much else. “These settings and designs,” adds Mitchell, “must typically be decided anew for each task a network is trained on.” It is hard to see nefarious unsupervised AI on the horizon.
The doom camp (AI will murder us) and the rapture camp (it will take us into the mind of God) share a common premise. Both groups extrapolate from past trends of exponential progress. Moore’s law—which is not really a law, but an observation—says that the number of transistors we can fit on a computer chip doubles every two years or so. This enables computer processing speeds to increase at an exponential rate. The futurist Ray Kurzweil asserts that this trend of accelerating improvement stretches back to the emergence of life, the appearance of Eukaryotic cells, and the Cambrian Explosion. Looking forward, Kurzweil sees an AI singularity—the rise of self-improving machine superintelligence—on the trendline around 2045.
The political scientist Philip Tetlock has looked closely at whether experts are any good at predicting the future. The short answer is that they’re terrible at it. But they’re not hopeless. Borrowing an analogy from Isaiah Berlin, Tetlock divides thinkers into hedgehogs and foxes. A hedgehog knows one big thing, whereas a fox knows many small things. A hedgehog tries to fit what he sees into a sweeping theory. A fox is skeptical of such theories. He looks for facts that will show he is wrong. A hedgehog gives answers and says “moreover” a lot. A fox asks questions and says “however” a lot. Tetlock has found that foxes are better forecasters than hedgehogs. The more distant the subject of the prediction, the more the hedgehogs’ performance lags.
Using a theory of exponential growth to predict an impending AI singularity is classic hedgehog thinking. It is a bit like basing a prediction about human extinction on nothing more than the Copernican principle. Kurzweil’s vision of the future is clever and provocative, but it is also hollow. It is almost as if huge obstacles to general AI will soon be overcome because the theory says so, rather than because the scientists on the ground will perform the necessary miracles. Gordon Moore himself acknowledges that his law will not hold much longer. (Quantum computers might pick up the baton. We’ll see.) Regardless, increased processing capacity might be just a small piece of what’s needed for the next big leaps in machine thinking.
When at Thanksgiving dinner you see Aunt Jane sigh after Uncle Bob tells a blue joke, you can form an understanding of what Jane thinks about what Bob thinks. For that matter, you get the joke, and you can imagine analogous jokes that would also annoy Jane. You can infer that your cousin Mary, who normally likes such jokes but is not laughing now, is probably still angry at Bob for spilling the gravy earlier. You know that although you can’t see Bob’s feet, they exist, under the table. No deep neural network can do any of this, and it’s not at all clear that more layers or faster chips or larger training sets will close the gap. We probably need further advances that we have only just begun to contemplate. “Enabling machines to form humanlike conceptual abstractions,” Mitchell declares, “is still an almost completely unsolved problem.”
There has been some concern lately about the demise of the corporate laboratory. Mitchell gives the impression that, at least in the technology sector, the corporate basic-research division is alive and well. Over the course of her narrative, labs at Google, Microsoft, Facebook, and Uber make major breakthroughs in computer image recognition, decision making, and translation. In 2013, for example, researchers at Google trained a network to create vectors among a vast array of words. A vector set of this sort enables a language-processing program to define and use a word based on the other words with which it tends to appear. The researchers put their vector set online for public use. Google is in some ways the protagonist of Mitchell’s story. It is now “an applied AI company,” in Mitchell’s words, that has placed machine thinking at the center of “diverse products, services, and blue-sky research.”
Google has hired Ray Kurzweil, a move that might be taken as an implicit endorsement of his views. It is pleasing to think that many Google engineers earnestly want to bring on the singularity. The grand theory may be illusory, but the treasures produced in pursuit of it will be real.
Also published by Forbes.com on WLF’s contributor page.